









TL;DR — Vos limites d’utilisation sur Claude ne dépendent pas du nombre de messages, mais du volume de tokens consommés. Et la plupart des utilisateurs en gaspillent entre 30 et 60 % sans le savoir. Le choix du modèle, la gestion de vos fichiers, la longueur de vos conversations et quelques réglages bien placés suffisent à multiplier votre capacité réelle par deux ou trois, sans changer d’abonnement. Cet article détaille chaque levier, du plus évident au plus méconnu.
Pourquoi vos tokens partent en fumée (et pourquoi personne ne vous l’a dit)
Vous êtes en pleine session de travail, Claude produit exactement ce que vous attendez, et soudain : le mur. « Vous avez atteint votre limite d’utilisation. » Le réflexe naturel ? Accuser Anthropic de radinerie ou envisager de passer au plan Max à 200 $/mois.
Mauvais diagnostic.
Le problème n’est presque jamais votre forfait. Le problème, c’est la façon dont vous consommez vos tokens. Anthropic ne facture pas au message : l’abonnement fonctionne comme un budget global en tokens, réinitialisé par fenêtre de 5 heures avec un plafond hebdomadaire. Et selon le modèle que vous sollicitez, un même budget vous offre cinq à vingt-cinq fois plus — ou moins — de marge de manœuvre.
Chez DeepDive, nous formons des professionnels à l’utilisation avancée de Claude depuis sa version 3.5. Ce qu’on observe sur le terrain, c’est que les mêmes erreurs reviennent systématiquement. Des PDF envoyés bruts, des conversations de 80 messages qui traînent en longueur, Opus activé pour reformuler trois phrases. Autant de tokens partis en fumée.
Voici comment reprendre le contrôle, en suivant les six axes stratégiques qui couvrent l’intégralité du sujet.
Choisir le bon modèle : le levier le plus rentable (et le plus ignoré)
C’est le raccourci que la majorité des utilisateurs ne prend jamais. Tous les modèles Claude consomment des tokens différemment — et la différence est massive.
La hiérarchie des coûts que vous devez connaître
Le tarif API donne l’échelle de grandeur : Haiku 4.5 coûte 1 $/5 $ par million de tokens (entrée/sortie), Sonnet 4.6 monte à 3 $/15 $, et Opus 4.6 (ou 4.7) se positionne à 5 $/25 $. En clair, Opus consomme cinq fois plus de budget que Haiku pour un même volume de texte traité. Sur un abonnement claude.ai, cette différence se traduit directement en nombre de messages possibles avant d’atteindre la limite.
Ce n’est pas de la théorie. Un développeur a documenté avoir épuisé 11 % de ses crédits hebdomadaires en trois prompts sur Opus. Trois.
La règle d’or : commencer par Haiku, monter si nécessaire
Haiku doit devenir votre réflexe par défaut. Recherche rapide, reformulation, brouillon, résumé, formatage de texte, discussions courantes : Haiku fait le travail en une fraction de seconde et pour une fraction du coût. La plupart des utilisateurs seraient surpris de constater que 40 à 50 % de leurs requêtes quotidiennes relèvent de ce niveau.
Sonnet prend le relais pour le travail quotidien sérieux. Rédaction structurée, modifications de code, analyse détaillée, synthèse de documents complexes : Sonnet couvre environ 80 % des besoins professionnels. Et depuis la version 4.6, ses performances en codage frôlent celles d’Opus (79,6 % contre 80,8 % sur SWE-bench) pour un coût inférieur de 40 %.
Opus se réserve à ce qui le justifie réellement : raisonnement profond sur des problèmes multi-étapes, décisions d’architecture logicielle, analyse scientifique de haut niveau, débogage de systèmes complexes. Si vous n’êtes pas en train de vous arracher les cheveux devant un problème que Sonnet n’a pas résolu, vous n’avez probablement pas besoin d’Opus.
L’alternative gratuite pour les tâches simples
Pour les développeurs, il existe un chemin de contournement radical : installer Ollama sur votre machine avec un modèle local comme Qwen3-Coder, et le connecter à votre workflow. Zéro token consommé sur votre abonnement. Évidemment, la qualité n’est pas comparable sur les tâches complexes, mais pour du formatage, de la complétion simple ou des transformations de code répétitives, c’est un filet de sécurité gratuit.
Gérer ses conversations comme un professionnel (pas comme un fil Twitter)
Voici le mécanisme que trop peu d’utilisateurs comprennent : à chaque message envoyé, Claude relit l’intégralité de l’historique de la conversation. Votre premier message coûte ses propres tokens. Votre dixième message coûte les siens plus la relecture des neuf précédents. Au vingtième échange, vous traînez une boule de neige qui peut peser des dizaines de milliers de tokens — avant même que Claude ne commence à réfléchir à votre requête.
Nouvelle conversation pour chaque nouveau sujet
La tentation est de rester dans le même fil pour « garder le contexte ». Résistez. Si vous passez de la rédaction d’un email à l’analyse d’un tableur, vous forcez Claude à transporter un contexte devenu inutile. Un nouveau chat, c’est un compteur remis à zéro.
Évitez les fils interminables
André Gentit le répète en formation chez DeepDive : au-delà de 15 à 20 messages dans un même fil, vous payez un impôt invisible qui dépasse souvent le coût de votre requête elle-même. L’historique s’accumule, et chaque nouvelle réponse de Claude — qui peut facilement peser 500 à 2 000 tokens — vient s’y ajouter pour être relue au tour suivant.
Le checkpoint : résumer avant de repartir
Quand un fil de conversation devient long mais que le contexte reste pertinent, demandez à Claude un résumé complet de l’état actuel du travail. Copiez ce résumé. Ouvrez un nouveau chat. Collez le résumé. Vous repartez avec 200 à 500 tokens de contexte au lieu de 15 000.
C’est une discipline, pas une astuce. Les utilisateurs avancés de Claude l’appliquent systématiquement.
Utilisez /clear ou /compact pour réinitialiser le contexte
Si vous travaillez dans Claude Code, les commandes /clear et /compact permettent de purger ou de compresser l’historique sans quitter votre session. C’est moins radical qu’un nouveau chat, mais ça limite efficacement l’effet boule de neige.
Renommez vos chats pour faciliter la recherche
Un détail qui fait gagner du temps (et donc des tokens) : un chat bien nommé est un chat que vous retrouvez sans devoir relancer une conversation identique. « Refonte header site client X » vaut mieux que « Nouveau Chat ».
Optimisation des fichiers et du contenu : là où se cachent les gaspillages massifs
La manière dont vous fournissez l’information à Claude a un impact direct — et souvent spectaculaire — sur votre consommation.
Privilégiez le texte brut (.txt, .md) aux PDF
C’est probablement le piège le plus coûteux et le plus répandu. Quand vous envoyez un PDF à Claude, chaque page est convertie en image, ce qui représente entre 1 500 et 3 000 tokens par page, rien que pour la conversion. Un document de 20 pages ? Vous venez de brûler entre 30 000 et 60 000 tokens avant que Claude n’ait lu la première phrase.
La solution est triviale : convertissez vos PDF en texte brut ou en Markdown avant de les soumettre. Vous pouvez même utiliser Claude lui-même pour cette conversion dans un premier chat dédié, puis démarrer votre vrai travail dans un chat vierge avec le texte propre.
Convertir les PDF en texte pour éviter le coût des images
Si vous n’avez pas d’outil de conversion sous la main, voici la méthode recommandée : téléchargez votre PDF dans un chat Claude, demandez « Convertis ce document en texte propre », copiez la sortie, puis ouvrez un nouveau chat et collez le texte. Vous évitez le surcoût du traitement visuel page par page.
Pour les pages web, l’extension de navigateur MarkDownload fait le travail directement en Markdown — idéal pour alimenter Claude avec du contenu web sans passer par la recherche intégrée (qui consomme elle aussi des tokens).
Remplacer les fichiers Excel par du CSV
Même logique que pour les PDF. Un fichier .xlsx contient du formatage, des métadonnées, des feuilles de style — autant d’informations que Claude doit parser et qui alourdissent votre contexte sans valeur ajoutée. Un export CSV contient les données, rien de plus.
Recadrez vos captures d’écran sur l’essentiel
Les images sont facturées au pixel. Une capture plein écran de 1 000 × 1 000 pixels consomme environ 1 334 tokens. Si vous ne recadrez que la zone pertinente — disons 200 × 200 pixels — vous tombez à 54 tokens. C’est vingt-cinq fois moins.
Mieux encore : si l’information peut être décrite sous forme de texte (un message d’erreur, un extrait d’interface), décrivez-la. Le texte coûte infiniment moins cher qu’une image.
Copier-coller uniquement les sections pertinentes
Ne collez pas un document de 15 pages si le problème se trouve dans un seul paragraphe. C’est une évidence que presque personne n’applique. Identifiez la section qui concerne votre requête, collez-la avec un minimum de contexte, et vous diviserez votre consommation par un facteur parfois supérieur à dix.
Techniques de prompting : l’art de dire plus avec moins
Le prompt engineering n’est pas qu’une question de qualité de résultat. C’est aussi — et peut-être surtout — une question d’efficacité économique.
Utilisez des balises XML pour structurer le contexte
Quand vous fournissez du contenu à Claude, encadrez-le avec des balises comme <document> et </document>, ou <code> et </code>. Ce n’est pas du formalisme : cela permet à Claude d’identifier immédiatement la structure de votre requête et de comprendre ce qui est du contexte, ce qui est une instruction, et ce qui est une question. Résultat : moins d’ambiguïté, moins d’allers-retours de clarification, moins de tokens gaspillés.
Demandez des réponses concises (sans commentaires)
Les longues explications pédagogiques de Claude sont appréciables quand on apprend. Quand on travaille, elles coûtent cher. Un « Code uniquement, sans commentaire » ou « En trois puces maximum » peut diviser le volume de tokens en sortie par deux ou trois. Et ces tokens de sortie pèsent dans votre budget autant que les tokens d’entrée — en fait, ils pèsent même davantage puisque le ratio sortie/entrée est de 5 pour 1 sur tous les modèles Claude actuels.
Regroupez plusieurs questions en un seul message
Trois messages séparés (« Peux-tu clarifier X ? », puis « Et Y ? », puis « Une dernière chose sur Z ? ») signifient que Claude relit l’historique trois fois au lieu d’une. Un seul message contenant les trois questions produit le même résultat pour un tiers du coût en relecture.
Astuce de formation DeepDive : rédigez vos prompts dans un éditeur de texte externe avant de les coller. Vous structurerez mieux, vous oublierez moins de détails, et vous éviterez les corrections en chaîne.
Demandez à Claude de poser des questions avant d’agir
Paradoxalement, ajouter un échange préliminaire peut réduire la consommation totale. Un « Avant de rédiger, pose-moi les trois questions qui te manquent pour produire un résultat optimal » coûte quelques centaines de tokens mais peut éviter une régénération complète à 3 000 tokens parce que le résultat ne correspondait pas à vos attentes.
Modifier un message existant au lieu de relancer
Si Claude se trompe ou part dans la mauvaise direction, ne répondez pas avec « Non, ce n’est pas ce que je voulais, recommence ». Cliquez sur « Modifier » (Edit) sur votre message précédent, corrigez votre formulation, et relancez. La différence ? Votre correction ne s’ajoute pas à l’historique — elle le remplace. Vous économisez tous les tokens de l’échange raté.
C’est un des conseils les plus simples de cet article, et probablement le plus sous-estimé.
Fonctionnalités et outils : désactiver ce qui vous coûte sans vous servir
Claude embarque un arsenal impressionnant de fonctionnalités. Le problème, c’est que chacune d’entre elles ajoute des tokens invisibles à chaque échange — même quand vous ne les utilisez pas activement.
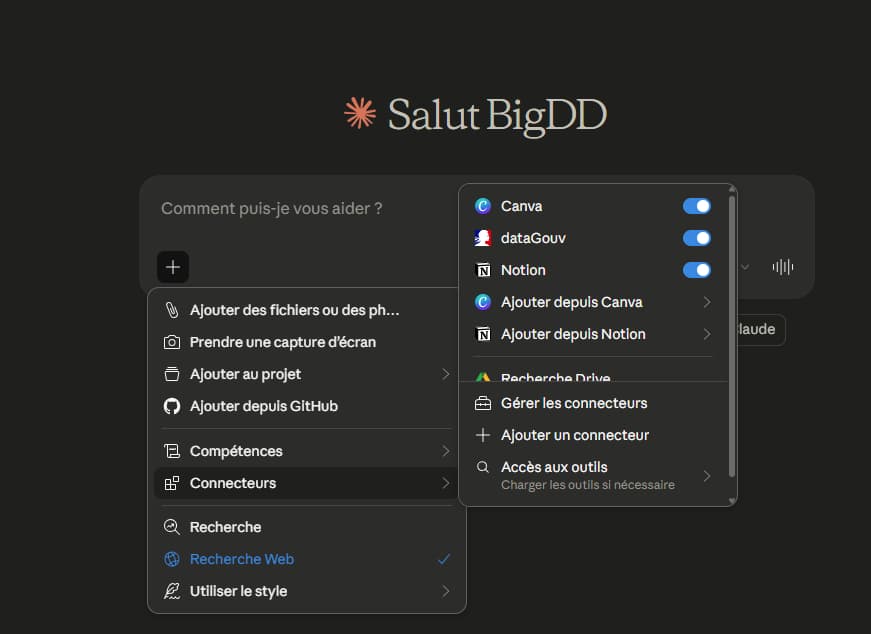
Projets : stocker les fichiers récurrents grâce à la mise en cache
Si vous téléchargez un document directement dans un chat, il est traité à chaque message. Si vous le placez dans la base de connaissances d’un Projet (Project Knowledge), Claude utilise un système de RAG (Retrieval-Augmented Generation) : les fichiers sont mis en cache et ne consomment pas vos limites de tokens à chaque interaction.
Pour les professionnels qui travaillent régulièrement avec les mêmes documents de référence — chartes éditoriales, spécifications techniques, guides de style — la différence est considérable. Le fichier est lu une fois, pas cinquante.
Skills : automatiser les workflows sans répétition
Si vous décrivez les mêmes préférences ou les mêmes instructions à chaque session (format de sortie, style de code, conventions de nommage), vous payez cette redondance en tokens à chaque fois. Créez un fichier SKILL.md qui contient ces instructions : Claude le chargera uniquement quand la tâche l’exige, au lieu de le relire systématiquement.
Désactivez les fonctionnalités inutiles
La recherche web, la mémoire globale, la Pensée approfondie (Extended Thinking), les Artifacts : chacune de ces fonctionnalités injecte des tokens supplémentaires dans votre contexte à chaque échange. Si votre tâche du moment n’en a pas besoin, désactivez-les temporairement. La Pensée approfondie, en particulier, génère des « thinking tokens » facturés comme des tokens de sortie — c’est-à-dire au tarif le plus élevé.
Et les connecteurs MCP (Google Drive, Slack, Notion, etc.) ? Si vous les laissez tous chargés en permanence, leurs définitions de schéma encombrent votre fenêtre de contexte en arrière-plan. Configurez-les sur « Charger les outils au besoin » (Load tools when needed) pour ne les invoquer que lorsque c’est pertinent.
Utiliser le CLI ou Ollama pour les tâches simples
Si vous êtes développeur, les outils en ligne de commande (comme gh pour GitHub) sont souvent plus économiques que les serveurs MCP, qui injectent des schémas JSON massifs dans votre contexte. Pour les tâches de code répétitives ou les opérations de formatage, un modèle local via Ollama ne consomme strictement aucun token de votre abonnement.
Planifier dans Chat, construire dans Cowork
Anthropic propose deux modes d’interaction avancés : le Chat classique et Cowork (mode autonome). La stratégie optimale consiste à utiliser le Chat — moins coûteux — pour réfléchir, planifier, valider la logique et affiner les spécifications. Vous ne basculez sur Cowork que pour la phase de construction finale, quand le cadre est posé et que Claude peut travailler de manière autonome sur un livrable défini.
Stratégie temporelle : quand vous travaillez compte autant que comment
C’est le levier que personne ne soupçonne, et il est pourtant officiel.
Privilégiez les heures creuses : soir et week-end
Anthropic l’a documenté publiquement : les limites d’utilisation sont plus restrictives pendant les heures de pointe, définies en semaine de 5h à 11h, heure du Pacifique. Pour la France et l’Europe francophone, cela correspond environ à la tranche 14h – 20h en semaine. Durant ces heures, votre budget en tokens fond significativement plus vite.
À l’inverse, les après-midis tardifs, les soirées et l’intégralité du week-end constituent des heures creuses où vos limites sont nettement plus généreuses.
Évitez les tâches lourdes en période de pic
L’analyse d’un rapport de 80 pages, une longue session itérative de codage, la refonte complète d’un document : ces opérations gourmandes en tokens devraient être planifiées en dehors des heures de pointe. Pas par superstition, mais parce que le même travail consommera littéralement moins de votre budget si vous le lancez à 21h plutôt qu’à 15h.
Automatiser les rapports via Cowork hors pic
Si vous disposez d’un forfait Pro ou Max, une stratégie particulièrement élégante consiste à programmer vos tâches automatisées dans Cowork pour qu’elles s’exécutent seules pendant les heures creuses. Un résumé hebdomadaire de vos messages Slack programmé pour le vendredi soir, une synthèse de documents lancée à 4h du matin : vous exploitez votre abonnement pendant que vous dormez, au moment où les limites sont les plus souples.
Le point de vue DeepDive : ce que cet article ne vous dit pas (mais que vous devriez savoir)
Optimiser ses tokens, c’est bien. Mais chez DeepDive, on observe un phénomène plus profond : la plupart des professionnels n’ont pas un problème de budget, ils ont un problème de méthode.
Un utilisateur qui maîtrise le prompt engineering — qui sait structurer une requête, choisir le bon modèle, découper son travail en tâches cohérentes — consomme naturellement deux à trois fois moins qu’un utilisateur qui « discute » avec Claude comme il discuterait avec un collègue en messagerie instantanée. Ce n’est pas une question de parcimonie, c’est une question de précision.
L’ironie, c’est que les guides d’optimisation de tokens prolifèrent, mais personne ne parle du vrai sujet : la compétence d’interaction avec l’IA. Savoir quand utiliser Haiku plutôt qu’Opus, structurer un prompt avec des balises XML, découper un projet en sessions courtes et ciblées — ce sont des compétences professionnelles, pas des astuces. Et elles feront la différence entre ceux qui subiront les limites de l’IA et ceux qui les feront travailler pour eux.
« Optimiser ses tokens, ce n’est pas être radin avec l’IA. C’est la preuve qu’on comprend comment elle fonctionne — et c’est exactement ce qui distingue un utilisateur d’un praticien. » — André Gentit, fondateur de DeepDive
Pour aller plus loin dans la maîtrise de Claude et des outils IA en contexte professionnel, retrouvez nos formations et analyses sur deep-dive.fr.

















André Gentit Formateur & Consultant en Stratégie Web et IA générative
Vous souhaitez bâtir une stratégie de communication efficace, booster la performance de votre site internet ou mieux comprendre les dynamiques des réseaux sociaux ?
👉 Avec DeepDive, je vous accompagne grâce à une expertise terrain (ex-dirigeant d’agence digitale depuis 2011) et une veille continue sur les nouvelles pratiques numériques.
👉 J’interviens auprès de TPE, PME et collectivités, mais aussi en écoles et organismes (CNAM, CCI, écoles de commerce) pour rendre le numérique accessible et opérationnel.
👉 Mes formations couvrent le webmarketing, l’e-commerce, l’IA générative appliquée et incluent également une sensibilisation aux risques liés aux usages du web en général, sans oublier les bonnes pratiques à mettre en œuvre avec l’intelligence artificielle.
Mon objectif : transmettre des savoirs concrets pour que chaque apprenant — étudiant, salarié, entrepreneur ou institution — puisse transformer le numérique et l’IA en véritable levier de réussite.
Découvrez mon petit robot PromptyBot qui vous propose des centaines de prompts optimisés


2 commentaires
trés bon , merci
very cool blog!! Excellent .. Amazing ..I am happy to find a lot of useful information here in the post, thanks for sharing